YOLOV8训练结果解析
YOLOV8 训练结果分析
概念理解
box_loss
优化边界框的位置和大小
Box Loss为边界框损失,是目标检测中用于衡量预测边界框与真实边界框之间差异的损失函数,用来衡量模型预测的边界框位置和大小的准确性,通常使用以下损失函数。值越小越好,接近0表示完美的边界框预测。
# IoU Loss交并比损失:
IoU = intersection_area / union_area
IoU_loss = 1 - IoU
# CIoU Loss完整IoU损失,考虑了预测与实际的中心点距离、以及长宽比等,YOLOV8默认采用CIoU完整IoU损失。
CIoU_loss = IoU_loss + distance_loss + aspect_ratio_loss
cls_loss
优化目标类别的识别准确性
Cls Loss为分类损失,是目标检测中用于衡量模型对目标类别预测准确性的损失函数,用来衡量模型正确识别目标类别(如鸭子)的能力。通常使用交叉熵损失函数。值越小越好,接近0表示完美的分类预测。
# Cross Entropy Loss交叉熵损失:
CE_loss = -∑(y_true * log(y_pred))
# Focal Loss焦点损失,用于处理类别不平衡问题:
Focal_loss = -α * (1 - y_pred)^γ * y_true * log(y_pred)
dfl_loss
优化边界框坐标的分布预测精度
Dfl Loss为分布焦点损失(Distribution Focal Loss),是YOLOv8中用于优化边界框回归的损失函数,通过建模边界框坐标的分布来提升回归精度。它比传统的回归损失更稳定,能更好地处理边界框预测的不确定性。值越小越好,接近0表示完美的分布预测。
# Distribution Focal Loss分布焦点损失:
# 将边界框坐标建模为分布,而不是单一值
DFL_loss = -log(softmax(pred_distribution)) * target_distribution
# 具体实现:
# 1. 将边界框坐标离散化为多个bin
# 2. 预测每个bin的概率分布
# 3. 计算预测分布与目标分布的焦点损失
precision
关注检测的准确性,避免误检
precision为精确率,是衡量模型预测准确性的指标,表示在所有被模型预测为正例(检测到鸭子)的样本中,真正是正例的比例。比如检测到了100只鸭子,但是只有92只是鸭子,其余8只为其他动物,则精确率为92%。
# TP(True Positive):真正例,正确检测到鸭子
# FP(False Positive):假正例,错误地将背景或其他物体检测为鸭子
# TN(True Negative):真负例,正确识别为背景
# FN(False Negative):假负例,漏检了鸭子
Precision = TP / (TP + FP)
recall
关注检测的完整性,避免漏检
recall为召回率,是衡量模型检测完整性的指标,表示在所有真实正例(实际存在的鸭子)中,被模型正确检测到的比例。比如实际有100只鸭子,但是模型只检测到了87只,则召回率为87%。
# TP(True Positive):真正例,正确检测到鸭子
# FP(False Positive):假正例,错误地将背景或其他物体检测为鸭子
# TN(True Negative):真负例,正确识别为背景
# FN(False Negative):假负例,漏检了鸭子
Recall = TP / (TP + FN)
mAP50
平衡精确率和召回率,IoU=0.5标准
mAP为mean Average Precision,称为平均精确率,mAP50则是在IoU阈值为50%的情况下的平均精度值。,是目标检测中最重要的评估指标,表示在IoU阈值为0.5时的平均精度。它综合考虑了精确率和召回率,通过计算不同置信度阈值下的精确率-召回率曲线下的面积得出。比如mAP50为95%,表示在IoU=0.5的阈值下,模型的平均检测精确率为95%。
# IoU(Intersection over Union):交并比
IoU = intersection_area / union_area
# mAP50计算过程:
# 1. 设置IoU阈值 = 0.5
# 2. 计算不同置信度下的precision-recall曲线
# 3. 计算曲线下的面积
mAP50 = Area_Under_Curve(Precision-Recall_Curve) at IoU=0.5
mAP50-95
更严格的综合评估标准
mAP50-95为平均精度50-95,是COCO数据集的标准评估指标,表示在IoU阈值从0.5到0.95(步长0.05)的所有阈值下mAP的平均值。它比mAP50更严格,要求模型在不同IoU阈值下都表现良好。比如mAP50-95为85%,表示模型在严格标准下的平均检测精确率为85%。
# mAP50-95计算过程:
# 1. 设置IoU阈值范围:[0.5, 0.55, 0.6, ..., 0.95]
# 2. 在每个IoU阈值下计算mAP
# 3. 对所有mAP值求平均
mAP50-95 = Average(mAP at IoU=0.5, mAP at IoU=0.55, ..., mAP at IoU=0.95)
结果分析
在模型训练结束后,会生成如下图所示的诸多文件,我们在此对文件进行解释,以理解如何使用这个训练生成的文件。
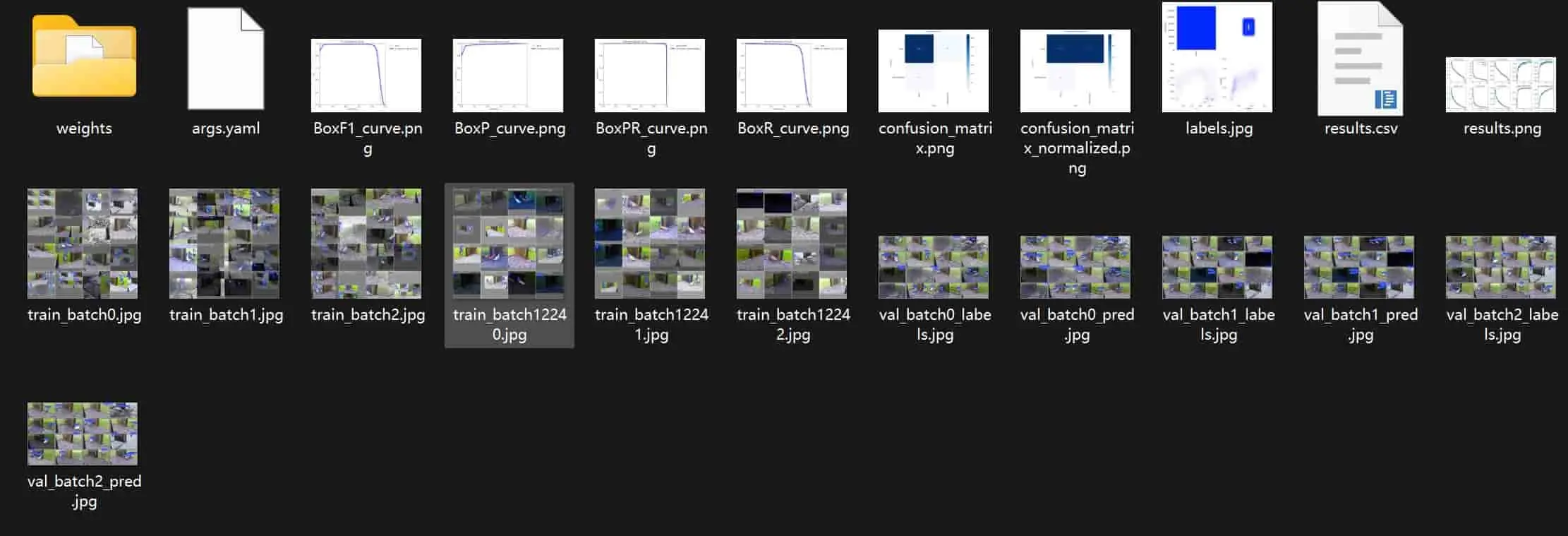
weights文件夹
weights文件夹下保存了我们此次训练获取到的最佳模型best.pt。
args.haml
模型训练采用的参数文件
BoxP_curve.png
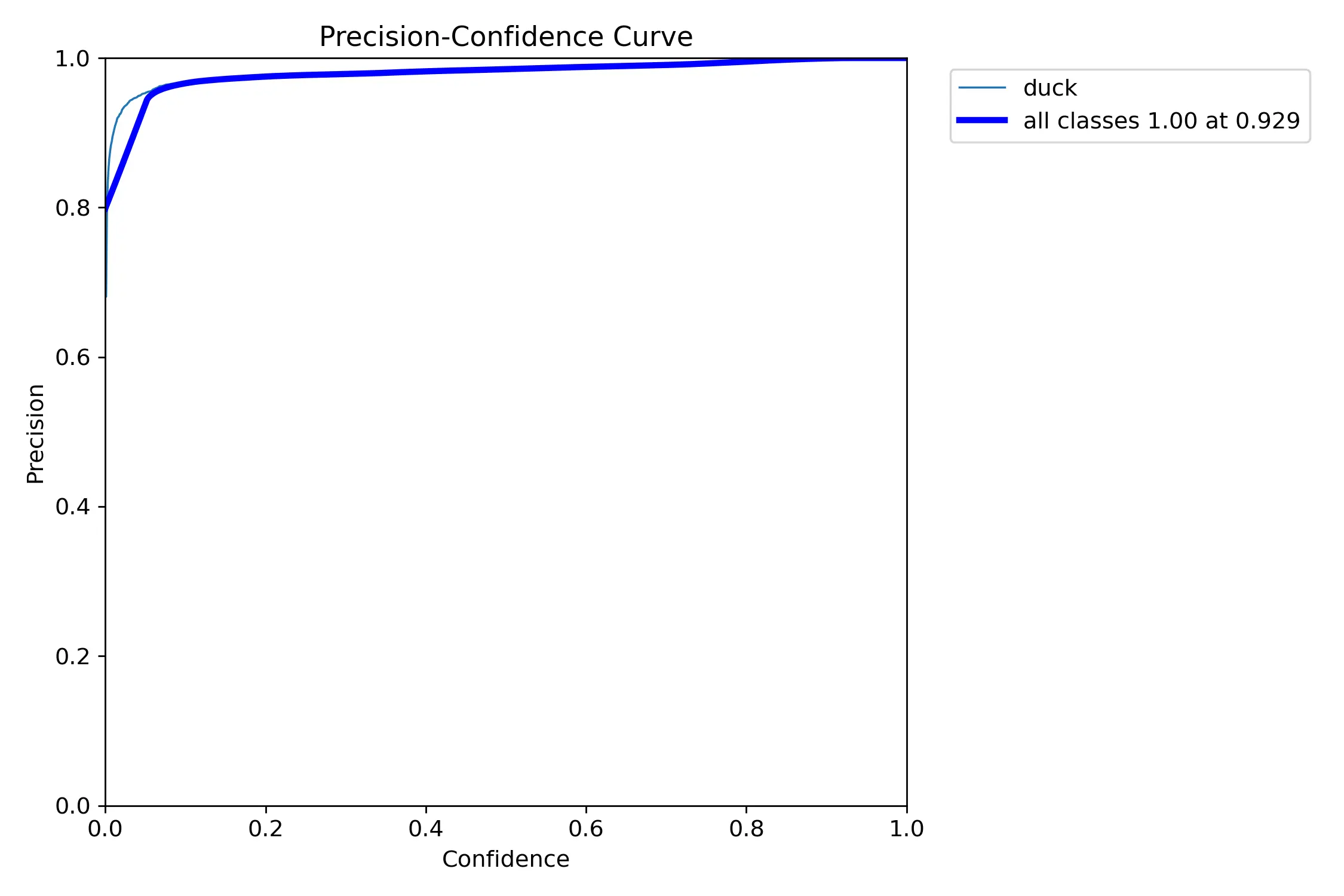
BoxP_curve.png是 YOLO 目标检测模型训练后生成的边界框精确度曲线图(Box Precision Curve)。这个图表展示了模型在不同置信度阈值下的精确度表现。
横轴为置信度,纵轴为精确度,随着选择的置信度增加,精确度也在增加,该曲线越平滑,代表模型性能越稳定。但需要注意的是随着置信度增加,召回率会有所下降,需要平衡精确度和召回率来选择最佳的置信度阈值。
当希望尽可能不要误检时,选择较高的置信度阈值
BoxR_curve.png
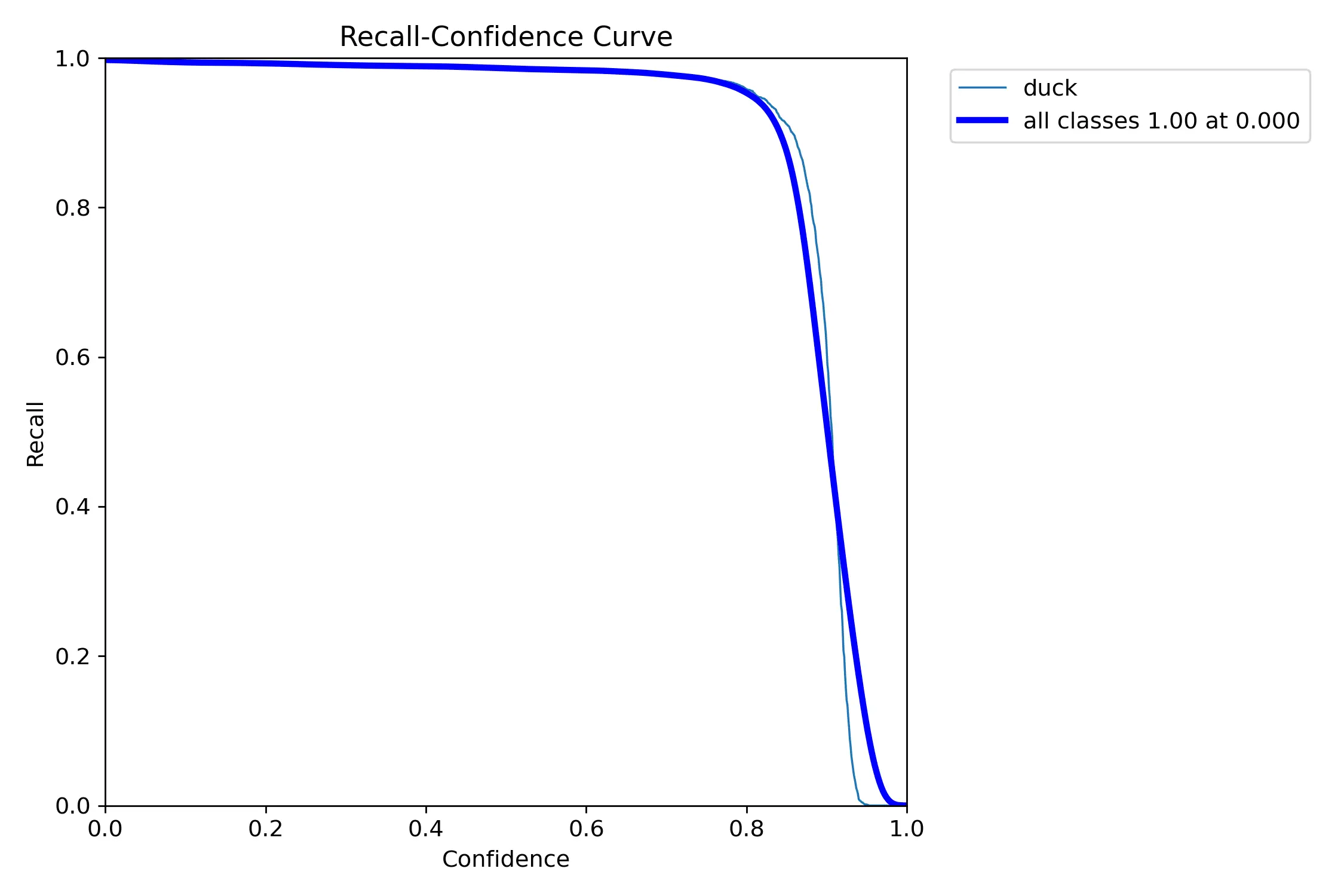
BoxR_curve.png 是 YOLO 目标检测模型训练后生成的边界框召回率曲线图(Box Recall Curve)。这个图表展示了模型在不同置信度阈值下的召回率表现。
横轴为置信度阈值,纵轴为召回率,随着选择的置信度增加,召回率逐渐下降,该曲线越平滑,代表模型性能越稳定。但需要注意的是随着置信度增加,精确度会有所提升,需要平衡召回率和精确度来选择最佳的置信度阈值。
当希望尽可能不要漏检时,选择较低的置信度阈值
BoxPR_curve.png
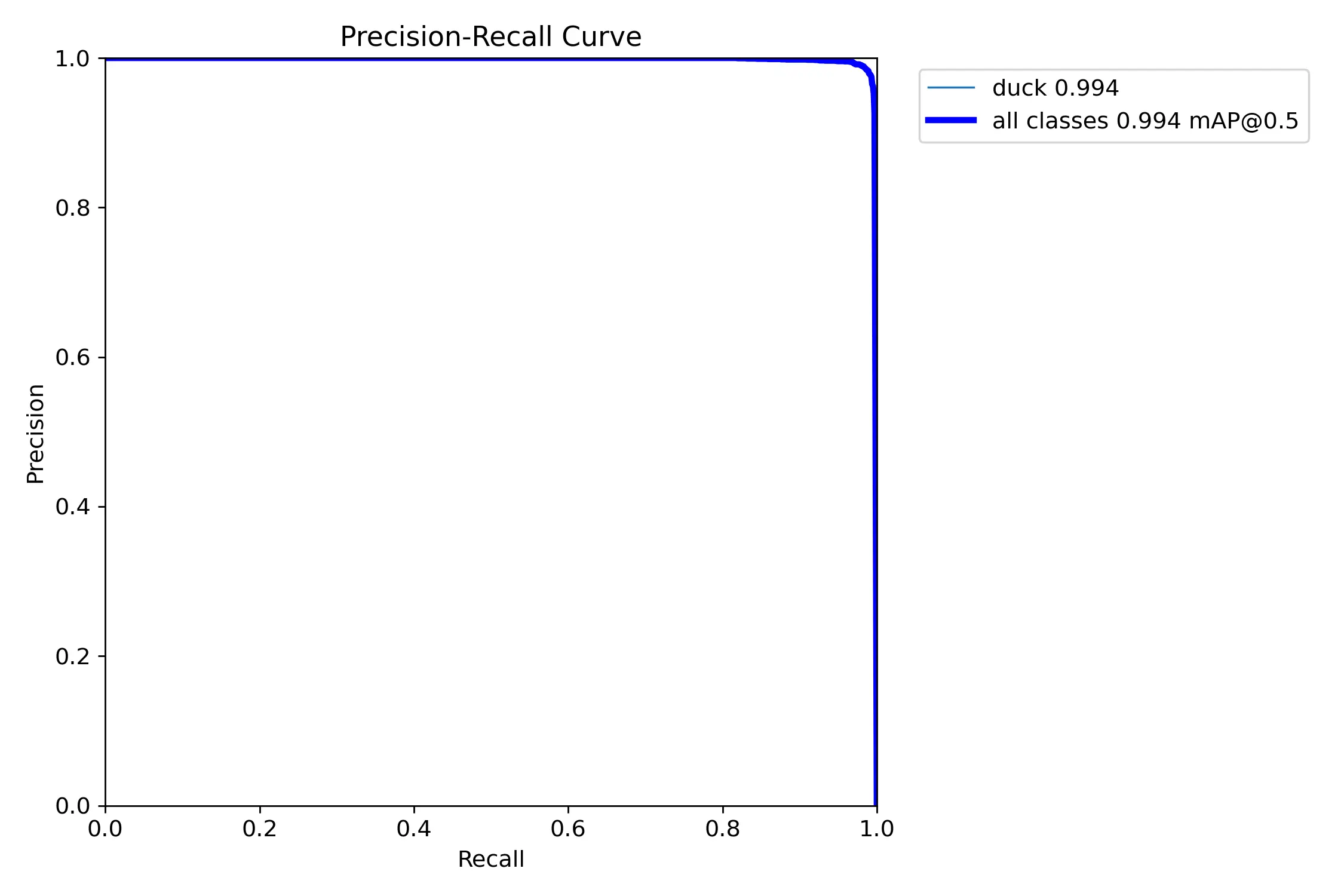
BoxPR_curve.png是 YOLO 目标检测模型训练后生成的边界框精确度-召回率曲线图(Box Precision-Recall Curve)。这个图表展示了模型在不同置信度阈值下精确度和召回率之间的关系。
横轴为召回率,纵轴为精确度,该曲线通常呈下降趋势,曲线越接近右上角代表模型性能越好。需要注意的是精确度和召回率之间存在权衡关系,提高其中一个指标通常会降低另一个指标,需要根据具体应用场景来选择合适的工作点。曲线整体越接近正方形越好。曲线越靠近右上角则代表越能够在保持高召回率的情况下达到高精确度。
BoxF1_curve.png
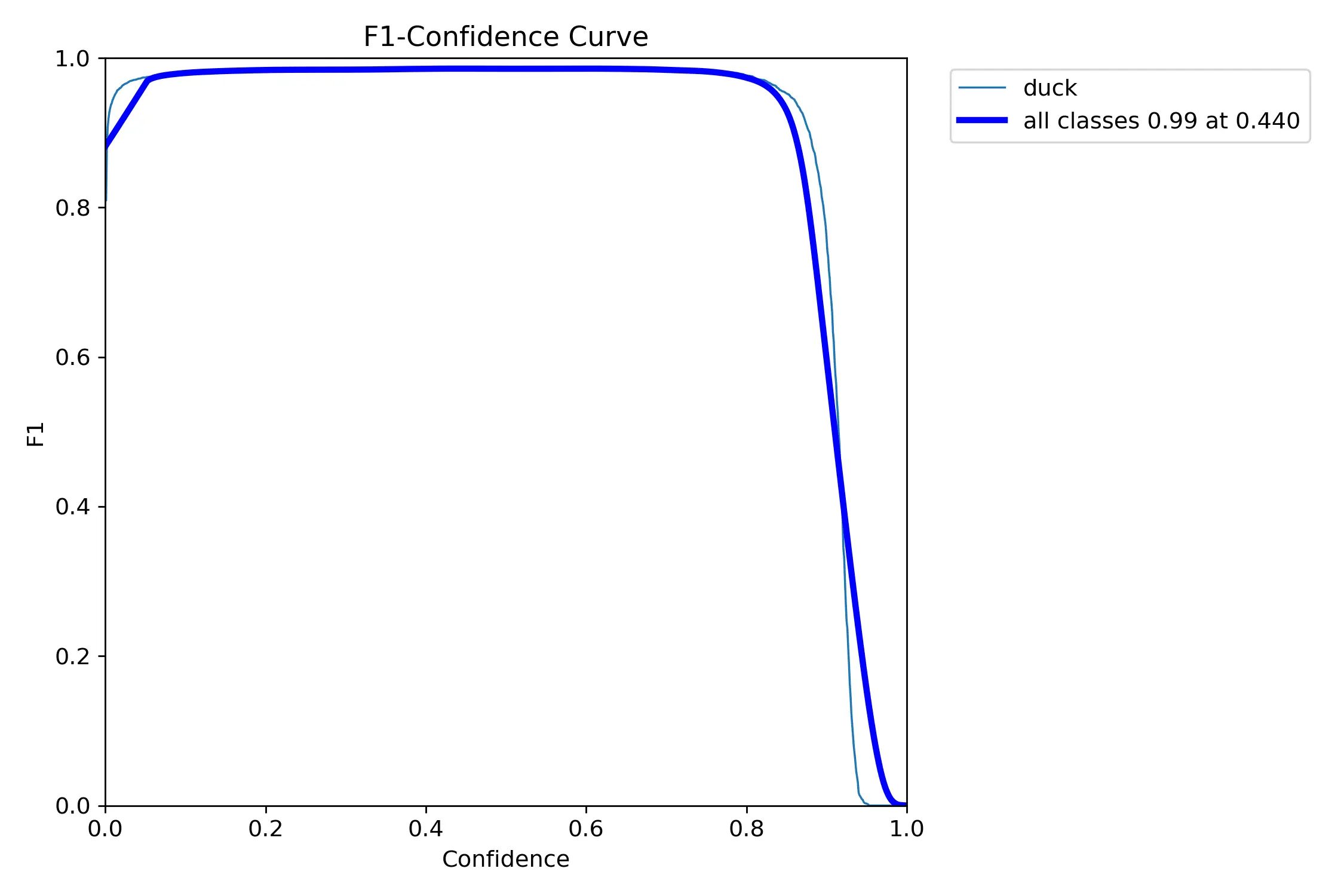
BoxF1_curve.png是 YOLO 目标检测模型训练后生成的边界框F1分数曲线图(Box F1-Score Curve)。这个图表展示了模型在不同置信度阈值下的F1分数表现。
横轴为置信度阈值,纵轴为F1分数,F1分数是精确度和召回率的调和平均数,该曲线通常呈现钟形分布,峰值点对应最佳的置信度阈值,在这个阈值点,模型在精确度和召回率之间达到了很好的平衡。F1分数曲线能够帮助找到精确度和召回率的最佳平衡点,为模型部署提供最优的置信度阈值选择。
这里为什么使用调和平均数呢,是因为当精确度或召回率其中一个很低时,算术平均数也可能仍然较高,调和平均数对低值更为敏感,只有当两个指标都很高时,F1分数才会比较高。
F1 = 2 / (1/Precision + 1/Recall)
confusion_matrix.png
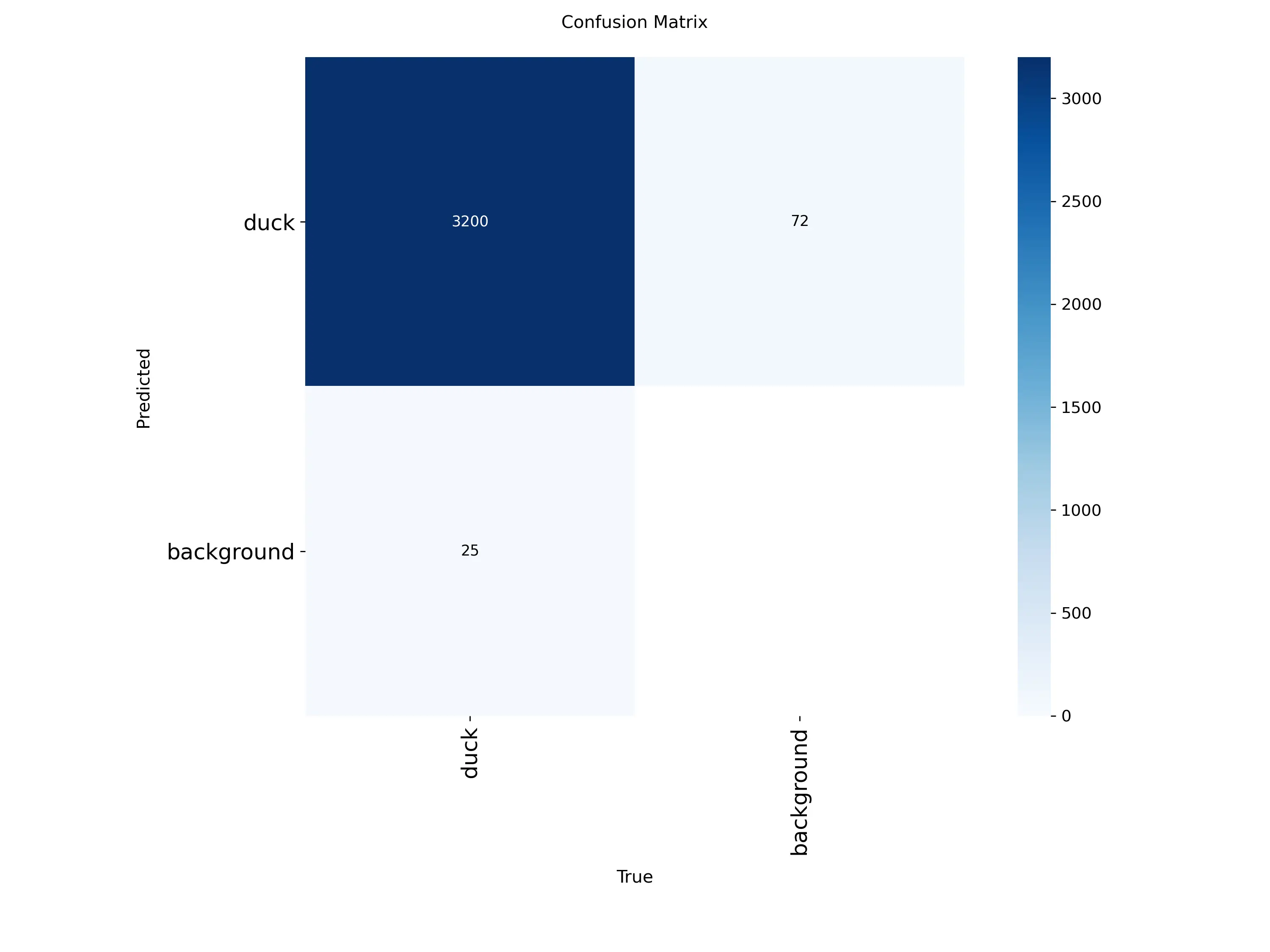
confusion_matrix.png是 YOLO 目标检测模型训练后生成的混淆矩阵图(Confusion Matrix)。这个图表展示了模型预测结果与真实标签之间的对比关系。
横轴为预测类别,纵轴为真实类别,对角线元素表示正确预测的数量,非对角线元素表示错误预测的数量。该矩阵越接近对角化,代表模型性能越好。但需要注意的是混淆矩阵能够直观显示模型的误检和漏检情况,为模型优化提供具体的改进方向。
左上象限:真正例(TP)- 正确检测到的鸭子数量;右上象限:假正例(FP)- 误检为鸭子的数量;左下象限:假负例(FN)- 漏检的鸭子数量;右下象限:真负例(TN)- 正确识别非鸭子区域的数量。
confusion_matrix_normalized.png
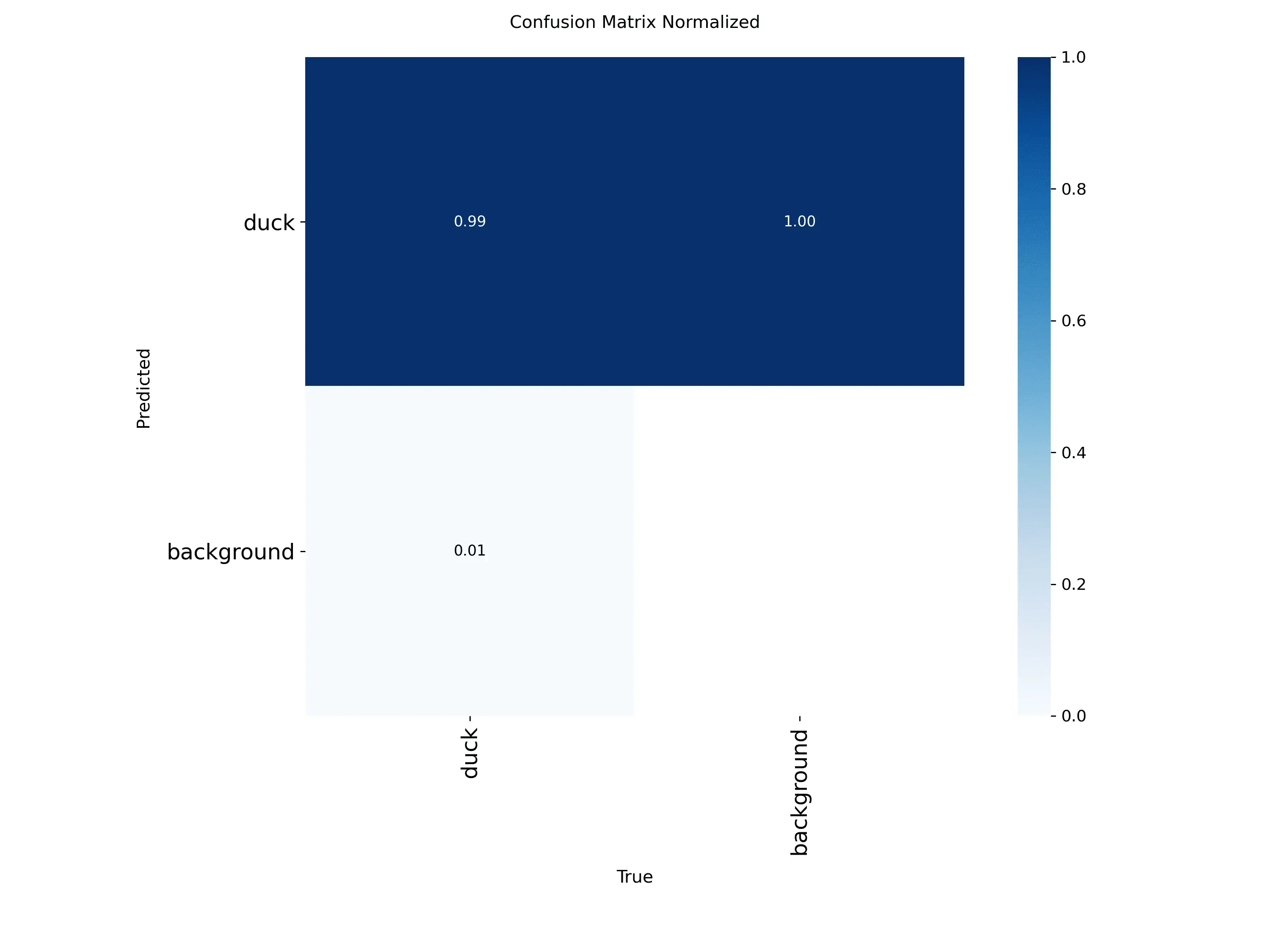
confusion_matrix_normalized.png是 YOLO 目标检测模型训练后生成的归一化混淆矩阵图(Normalized Confusion Matrix)。这个图表以百分比形式展示了模型预测结果与真实标签的对比关系。
横轴为预测类别,纵轴为真实类别,每个数值表示该类别的预测准确率百分比,对角线应该接近100%。该矩阵能够更直观地比较不同类别的性能表现。归一化处理使得不同类别之间的性能更容易进行比较,有助于识别模型的优势和劣势。
labels.jpg
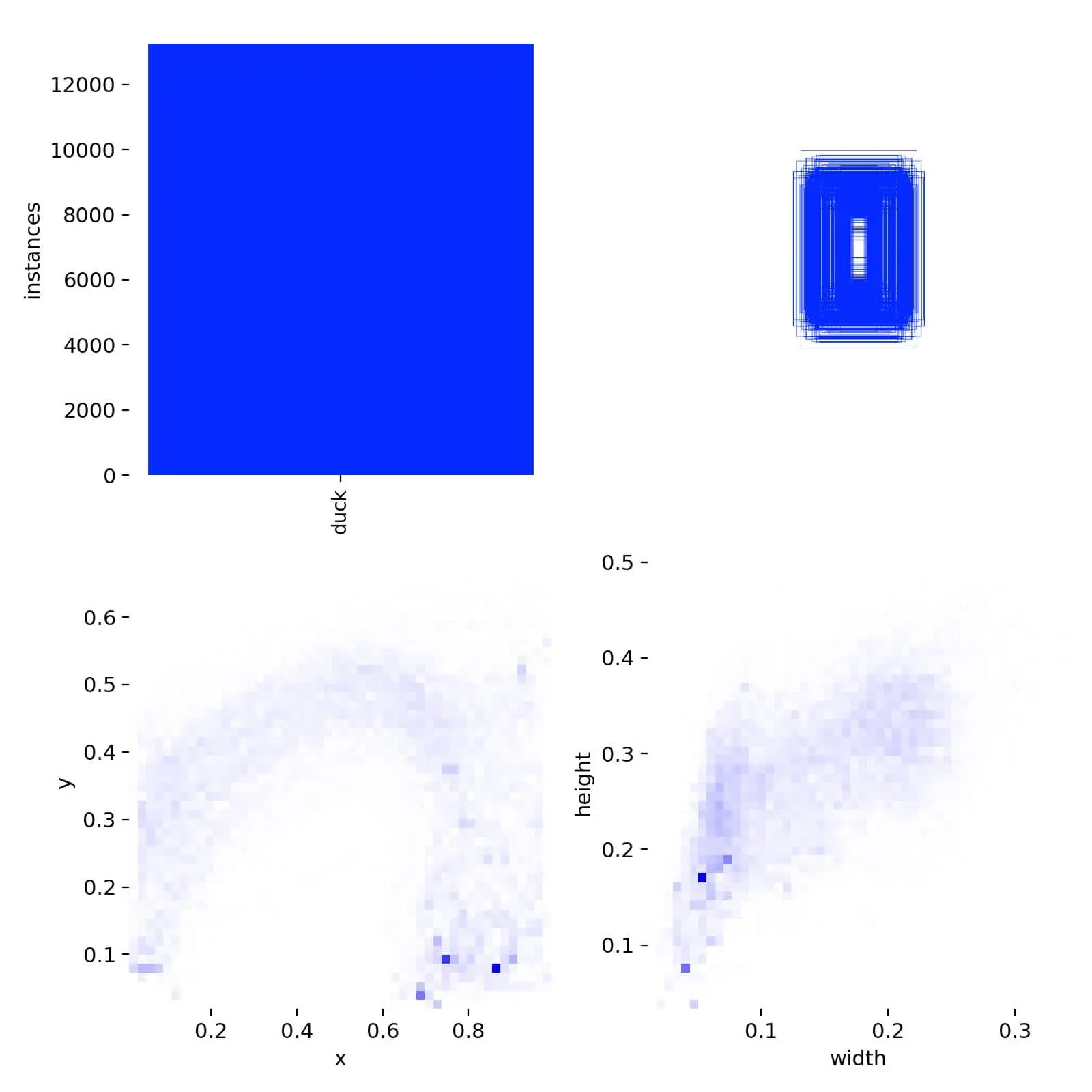
labels.png是YOLO 目标检测模型训练后生成的标签的分布图。
左上象限是对应检测类型的样本数;右上象限是检测框的尺寸和数量;左下象限是检测框中心点在全图中的位置;右下象限是图中的检测目标相对于整幅图的高宽比例。
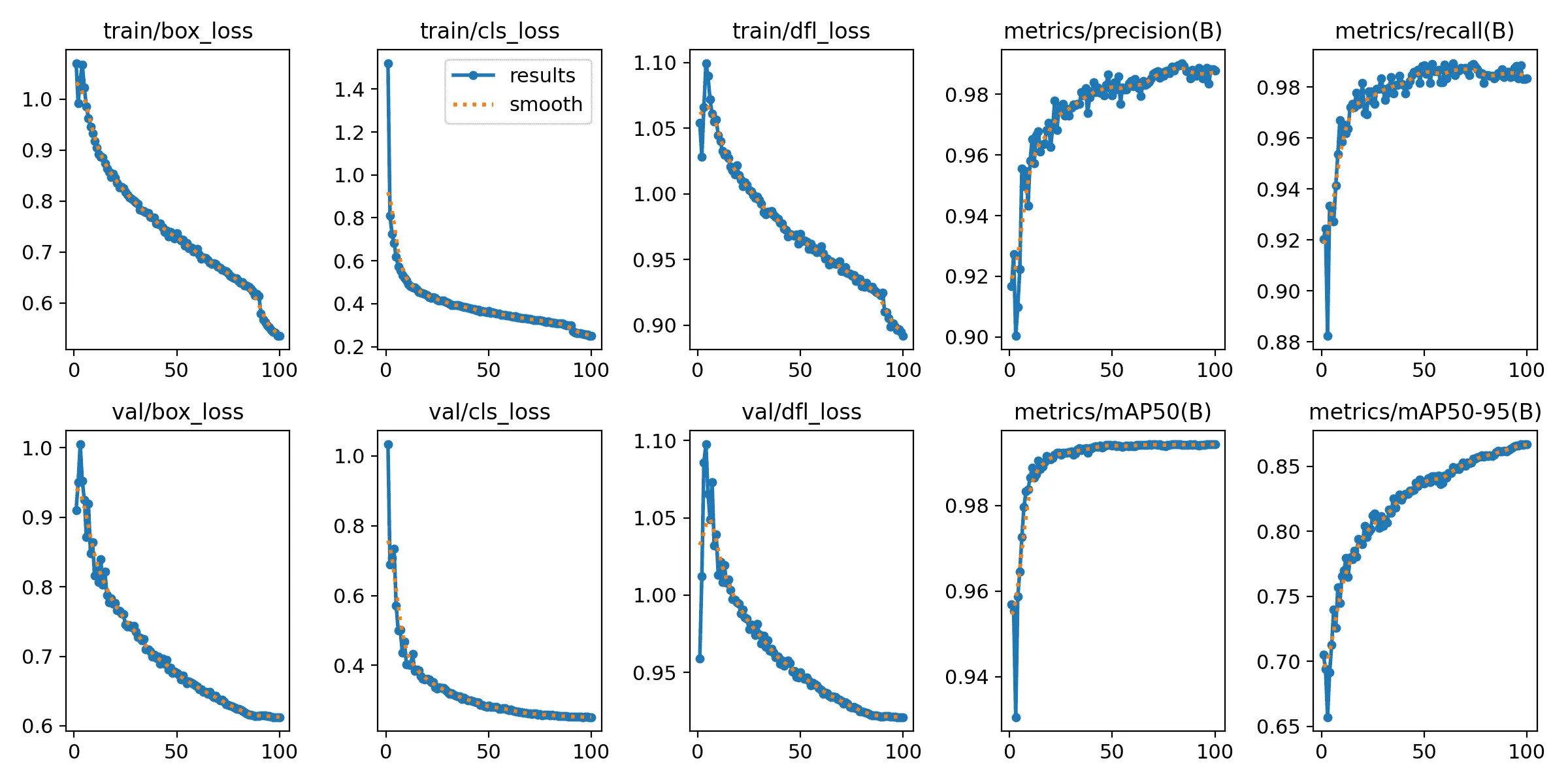
results.csv
results.csv是YOLO目标检测模型训练后生成的结果。 在目标检测任务中,我们需要对测试集中的图像进行目标检测,并将检测结果输出。results.txt就是将模型在测试集上的检测结果保存在文本文件中得到的文件。对于每张测试图像,results.txt会记录检测出的目标框的位置坐标、目标类别、以及置信度分数等信息。
**每行含义分别是:**训练次数、GPU消耗、训练集边界框损失、训练集目标检测损失、训练集分类损失、训练集总损失、targets目标、输入图片大小、Precision、Recall、mAP@.5、mAP@.5:.95、验证集边界框损失、验证集目标检测损失、验证机分类损失

train_batch*.jpg
训练集的数据增强展示
val_batch*_labels.jpg
验证集第*轮的实际标签
val_batch*_pred.jpg
验证集第*轮的预测标签
results.png
results.png 是results.csv的可视化呈现。
经验
高精确度,低召回率会导致模型过于保守,会漏检;
低精确度,高召回率会导致模型过于激进,会误检;
通过数据增强,可能在一定程度上优化mAP指标;